处理分类数据
目前为止,我们处理的都是数值型变量。但是真实世界的数据集通常都含有分类型变量(categorical value)的特征。当我们讨论分类型数据时,我们不区分其取值是否有序。比如T恤尺寸是有序的,因为XL>L>M。而T恤颜色是无序的。
在讲解处理分类数据的技巧之前,我们先创建一个新的DataFrame对象:

上面创建的数据集含有无序特征(color),有序特征(size)和数值型特征(price)。最后一列存储的是类别。在本书中类别信息都是无序的。
映射有序特征
为了保证学习算法能够正确解释有序特征(ordinal feature),我们需要将分类型字符串转为整型数值。不幸地是,并没有能够直接调用的方法来自动得到正确顺序的size特征。因此,我们要自己定义映射函数。在接下来的简单的示例,假设我们知道特征取值间的不同,比如 XL=L+1=M+2。
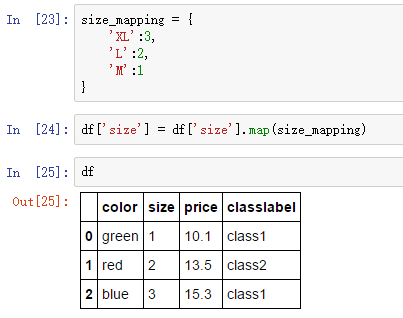
如果我们还想将整型变量转换回原来的字符串表示,我们还可以定义一个反映射字典 inv_size_mapping={v: k for k, v in size_mapping.items()}。
对类别进行编码
许多机器学习库要求类别是整型数值。虽然sklearn中大部分Estimator都能自动将类别转为整型,我还是建议大家手动将类别进行转换。对类别进行编码,和上一节中转化序列特征很相似。但不同的是类别是无序的,所以我们可以从0开始赋整数值:

接下来我们可以利用映射字典对类别进行转换:
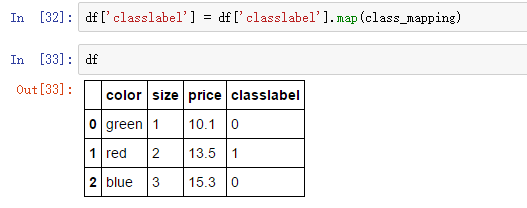
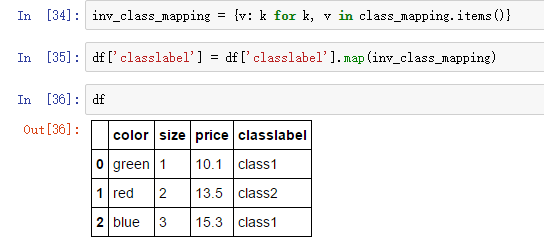
得到整型类别值,也可以用映射字典转为原始的字符串值:
上面是我们自己手动创建的映射字典,sklearn中提供了LabelEncoder类来实现类别的转换:

fit_transform方法是fit和transform两个方法的合并。我们还可以调用inverse_transform方法得到原始的字符串类型值:

对离散特征进行独热编码
前面一节我们使用字典映射来转化有序特征,由于sklearn中Estimator把类型信息看做无序的,我们使用LabelEncoder来进行类别的转换。而对于无序的离散特征,我们也可以使用LabelEncoder来进行转换:

现在我们将无序离散特征转换为整型了,看起来下一步就是直接训练模型了。如果你这样想,恭喜你,你犯了一个很专业的错误。在处理分类型数据(categorical data)时,这是很常见的错误。你能发现问题所在吗?虽然“颜色”这一特征的值不含有顺序,但是由于进行了以下转换:

学习算法会认为‘green’比‘blue’大,‘red’比‘green’大。而这显然是不正确的,因为本身颜色是无序的!模型错误的使用了颜色特征信息,最后得到的结果肯定不是我们想要的。
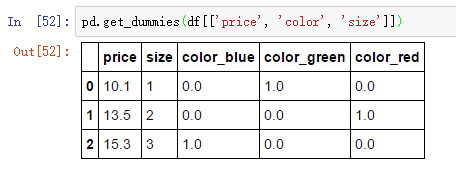
那么如何处理无序离散特征呢?常用的做法是独热编码(one-hot encoding)。独热编码会为每个离散值创建一个哑特征(dummy feature)。什么是哑特征呢?举例来说,对于‘颜色’这一特征中的‘蓝色’,我们将其编码为[蓝色=1,绿色=0,红色=0],同理,对于‘绿色’,我们将其编码为[蓝色=0,绿色=1,红色=0],特点就是向量只有一个1,其余均为0,故称之为one-hot。
在sklearn中,可以调用OneHotEncoder来实现独热编码:

在初始化OneHotEncoder时,通过categorical_features参数设置要进行独热编码的列。还要注意的是OneHotEncoder的transform方法默认返回稀疏矩阵,所以我们调用toarray()方法将稀疏矩阵转为一般矩阵。我们还可以在初始化OneHotEncoder时通过参数sparse=False来设置返回一般矩阵。
除了使用sklearn中的OneHotEncoder类得到哑特征,我推荐大家使用pandas中的get_dummies方法来创建哑特征,get_dummies默认会对DataFrame中所有字符串类型的列进行独热编码: