利用随机森林评估特征重要性
在前面一节,你学习了如何利用L1正则将不相干特征变为0,使用SBS算法进行特征选择。另一种从数据集中选择相关特征的方法是利用随机森林。
随机森林能够度量每个特征的重要性,我们可以依据这个重要性指标进而选择最重要的特征。sklearn中已经实现了用随机森林评估特征重要性,在训练好随机森林模型后,直接调用feature_importances属性就能得到每个特征的重要性。
下面用Wine数据集为例,我们训练一个包含10000棵决策树的随机森林来评估13个维度特征的重要性(第三章我们就说过,对于基于树的模型,不必对特征进行标准化或归一化):
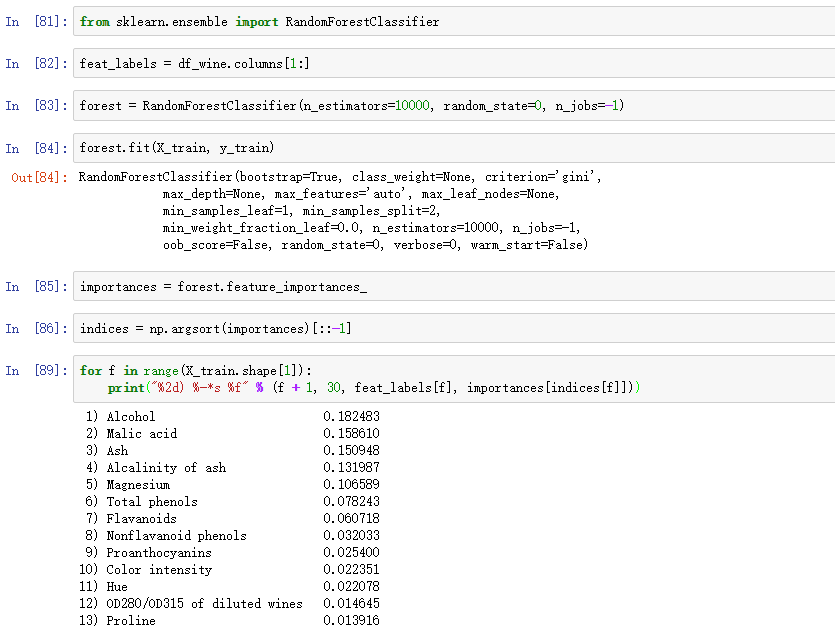
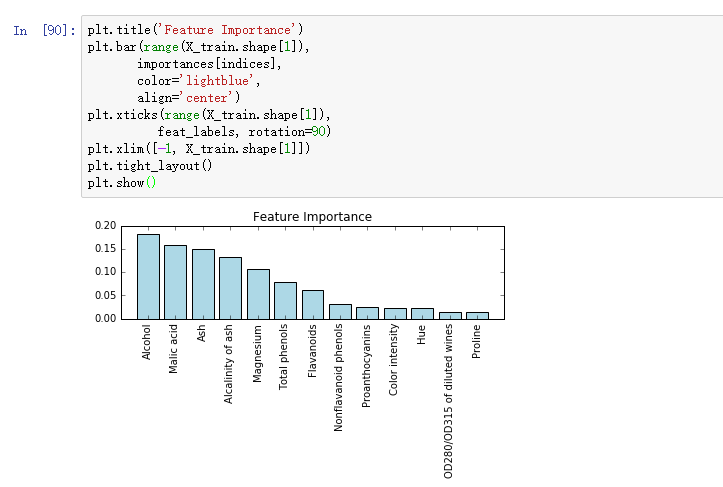
我们可以得出结论:‘Alcohol’是最能区分类别的特征。有趣地是,重要性排名前三的特征也在SBS的最优5特征子集中。
sklearn的随机森林实现,包括一个transform方法能够基于用户给定的阈值进行特征选择,所以如果你要用RandomFroestClassifier作为特征选择器,这就很easy了。举个例子:设置阈值为0.15,会选择出三个维度特征,Alcohol、Malic acid和Ash。