集成学习
集成学习背后的思想是将不同的分类器进行组合得到一个元分类器,这个元分类器相对于单个分类器拥有更好的泛化性能。比如,假设我们从10位专家那里分别得到了对于某个事件的预测结果,集成学习能够对这10个预测结果进行组合,得到一个更准确的预测结果。
后面我们会学到,有不同的方法来创建集成模型,这一节我们先解决一个基本的问题:为什么要用集成学习?她为什么就比单个模型效果要好呢?
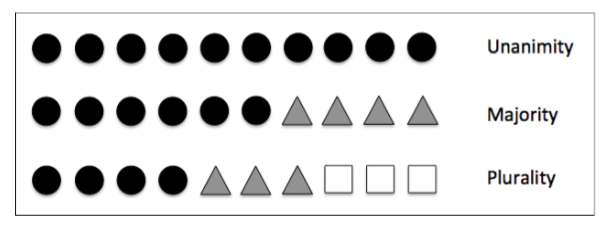
本书是为初学者打造的,所以集成学习这里我们也只关注最基本的集成方法:投票法(majority voting)。投票法意味着我们在得到最后的预测类别时,看看哪个类别是大多数单分类器都预测的,这里的大多数一般是大于50%。更严格来说,投票法只适用于二分类,当然他很容易就扩展到多分类情况: 多数表决(plurality voting).
下图展示了一个投票法的例子,一共10个基本分类器:
我们先用训练集训练m个不同的分类器, 这里的分类器可以是决策树、SVM或者LR等。我们当然也可以用同一种分类器,只不过在训练每一个模型时用不同的参数或者不同的训练集(比如自主采样法)。随机森林就是一个采用这种策略的例子,它由不同的决策树模型构成。这图展示了用投票策略的集成方法步骤:
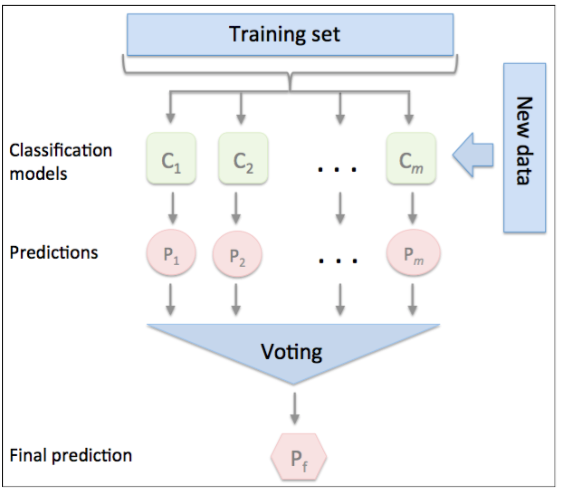
投票策略非常简单,我们收集每个单分类器的预测类别
,将票数最多的
作为预测结果:

以二分类为例,类别class1=-1, class2=+1, 投票预测的过程如下, 把每个单分类器的预测结果相加,如果值大于0,预测结果为正类,否则为负类:

读到这里,我想大家都有一个疑问:凭啥集成学习就比单分类器效果好?道理很简单(一点点组合数学知识),假设对于一个二分类问题,有n个单分类器,每个单分类器有相等的错误率,并且单分类器之间相互独立,错误率也不相关。 有了这些假设,我们可以计算集成模型的错误概率:

如果n=11,错误率为0.25,要想集成结果预测错误,至少要有6个单分类器预测结果不正确,错误概率是:

集成结果错误率才0.034哦,比0.25小太多。继承结果比单分类器好,也是有前提的,就是你这个单分类器的能力不能太差,至少要比随机猜测的结果好一点,至少。
从下图可以看出,只要单分类器的表现不太差,集成学习的结果总是要好于单分类器的。
