K折交叉验证评估模型性能
训练机器学习模型的关键一步是要评估模型的泛化能力。如果我们训练好模型后,还是用训练集取评估模型的性能,这显然是不符合逻辑的。一个模型如果性能不好,要么是因为模型过于复杂导致过拟合(高方差),要么是模型过于简单导致导致欠拟合(高偏差)。可是用什么方法评价模型的性能呢?这就是这一节要解决的问题,你会学习到两种交叉验证计数,holdout交叉验证和k折交叉验证, 来评估模型的泛化能力。
holdout method
评估模型泛化能力的典型方法是holdout交叉验证(holdout cross validation)。holdout方法很简单,我们只需要将原始数据集分割为训练集和测试集,前者用于训练模型,后者用于评估模型的性能。
不过,在训练模型这一步,我们非常关心如何选择参数来提高模型的预测能力,而选择参数这一步被称为模型选择(model selection,译者注:不少资料将选择何种模型算法称为模型选择),参数选择是非常重要的,因为对于同一种机器学习算法,如果选择不同的参数(超参数),模型的性能会有很大差别。
如果在模型选择的过程中,我们始终用测试集来评价模型性能,这实际上也将测试集变相地转为了训练集,这时候选择的最优模型很可能是过拟合的。
更好的holdout方法是将原始训练集分为三部分:训练集、验证集和测试集。训练机用于训练不同的模型,验证集用于模型选择。而测试集由于在训练模型和模型选择这两步都没有用到,对于模型来说是未知数据,因此可以用于评估模型的泛化能力。下图展示了holdout方法的步骤:
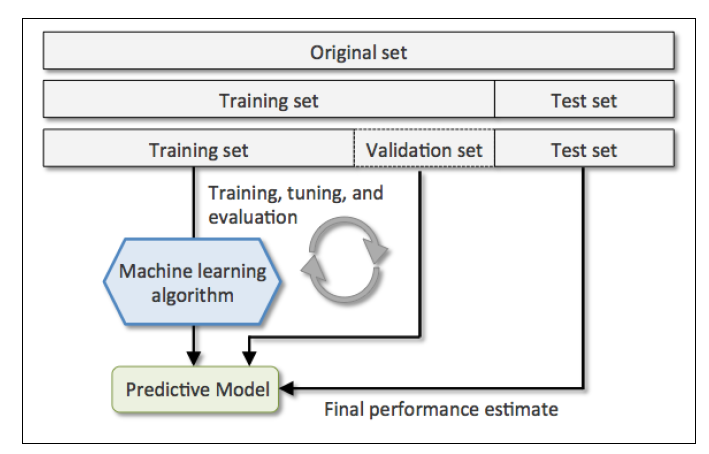
当然holdout方法也有明显的缺点,它对数据分割的方式很敏感,如果原始数据集分割不当,这包括训练集、验证集和测试集的样本数比例,以及分割后数据的分布情况是否和原始数据集分布情况相同等等。所以,不同的分割方式可能得到不同的最优模型参数。
下一节,我们会学习到一种鲁棒性更好的模型评估方法,k折交叉沿则,即重复k次holdout方法提高鲁棒性。
k折交叉验证
k折交叉验证的过程,第一步我们使用不重复抽样将原始数据随机分为k份,第二步 k-1份数据用于模型训练,剩下那一份数据用于测试模型。然后重复第二步k次,我们就得到了k个模型和他的评估结果(译者注:为了减小由于数据分割引入的误差,通常k折交叉验证要随机使用不同的划分方法重复p次,常见的有10次10折交叉验证)。
然后我们计算k折交叉验证结果的平均值作为参数/模型的性能评估。使用k折交叉验证来寻找最优参数要比holdout方法更稳定。一旦我们找到最优参数,要使用这组参数在原始数据集上训练模型作为最终的模型。
k折交叉验证使用不重复采样,优点是每个样本只会在训练集或测试中出现一次,这样得到的模型评估结果有更低的方法。
下图演示了10折交叉验证:
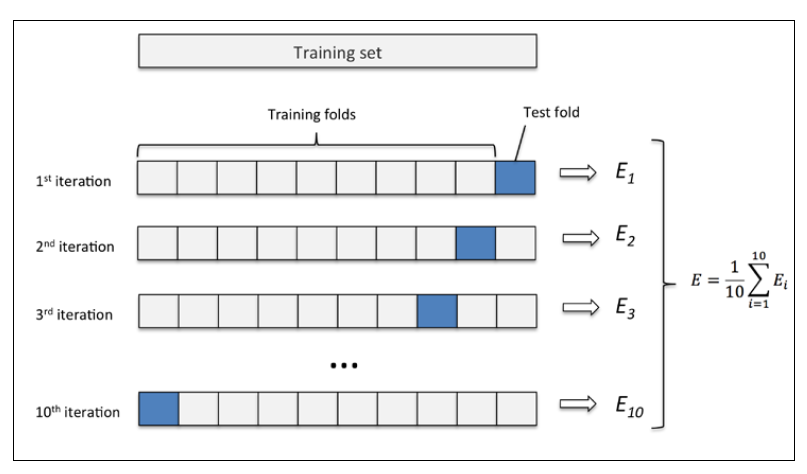
至于k折中的k到底设定为多少,这个又是一个调参的过程,当然了,这一步很少有人会调参,一般都是用10.但是如果你的数据集特别小,我们当然希望训练集大一点,这时候就要设定大一点的k值,因为k越大,训练集在整个原始训练集的占比就越多。但是呢,k也不能太大,一则是导致训练模型个数过多,二则是k很大的情况下,各个训练集相差不多,导致高方差。要是你的数据集很大,那就把k设定的小一点咯,比如5.
其实呢,在将原始数据集划分为k部分的过程中,有很多不同的采样方法,比如针对非平衡数据的分层采样。分层采样就是在每一份子集中都保持原始数据集的类别比例。比如原始数据集正类:负类=3:1,这个比例也要保持在各个子集中才行。sklearn中实现了分层k折交叉验证哦:
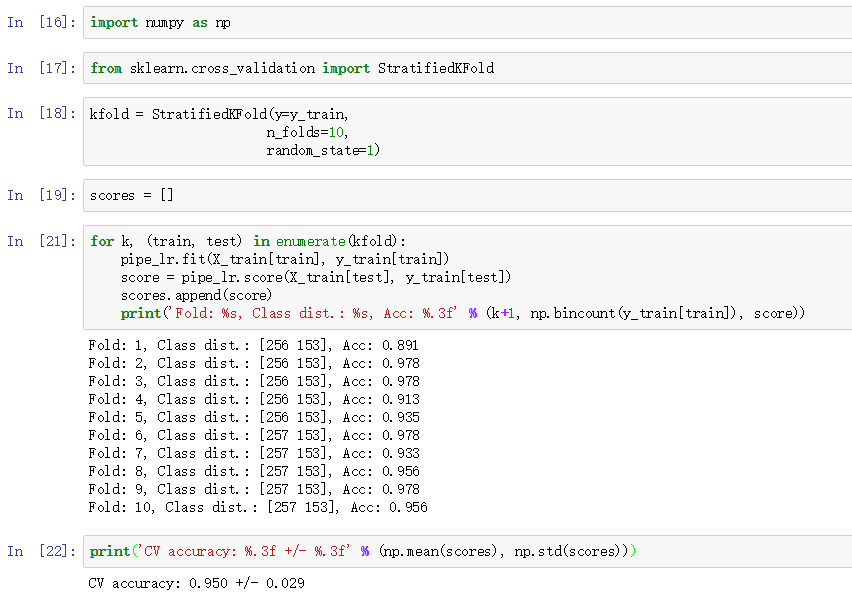
sklearn就是这么方便,此外,更人性化的是sklearn还实现了一个直接得到交叉验证评估结果的方法cross_val_score(内部同样是分层k折交叉验证):
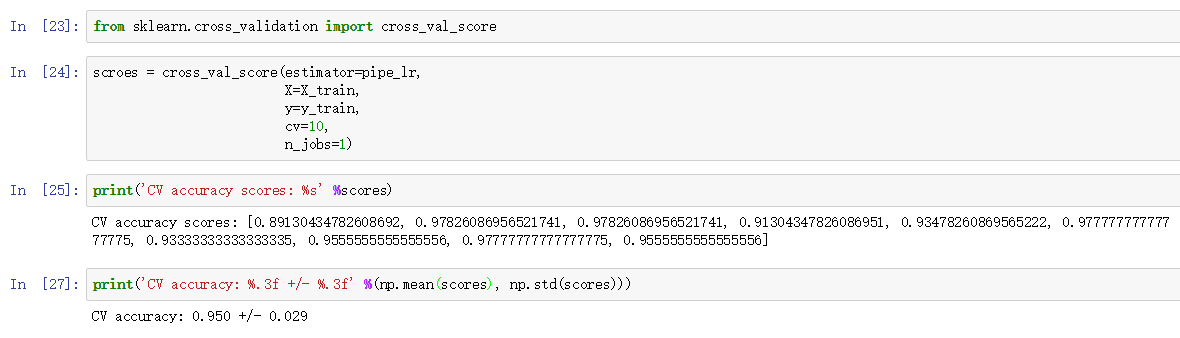
cross_val_score方法还支持并行计算。
Note 交叉验证是如何评估泛化能力的方差,这个问题超出了本书的范围,如果你感兴趣,可以阅读 Analysis of Variance of Cross-validation Estimators of the Generalized Error. Journal of Machine Learning Research, 6:1127-1168, 2005