使用正则化解决过拟# 使用正则化解决过拟 # 使用正则化解决过拟# 使用正则化解决过拟 合
过拟合(overfitting)是机器学习中很常见的问题,指的是一个模型在训练集上表现很好但是泛化能力巨差(在测试集上的表现糟糕)。如果一个模型饱受过拟合困扰,我们也说此模型方差过高,造成这个结果的原因可能是模型含有太多参数导致模型过于复杂。同样,模型也可能遇到欠拟合(underfitting)问题,我们也说此模型偏差过高,原因是模型过于简单不能学习到训练集中数据存在的模式,同样对于测试集表现很差。
虽然到目前为止我们仅学习了用于分类任务的几种线性模型,过拟合和欠拟合问题可以用一个非线性决策界很好的演示:
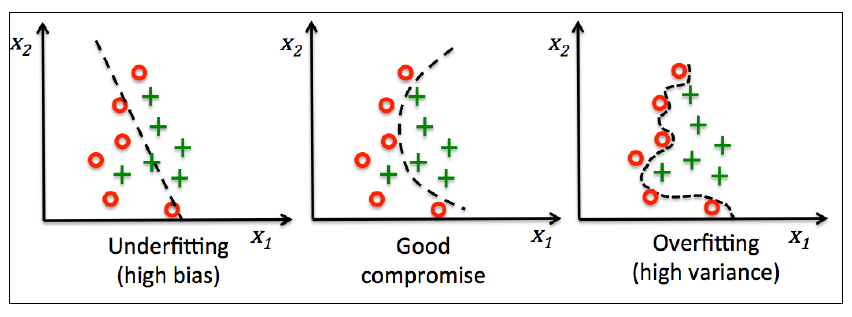
怎样找到bias-variance之间的平衡,常用的方法是正则化(regularization)。正则化是解决特征共线性、过滤数据中噪音和防止过拟合的有用方法。正则化背后的原理是引入额外的信息(偏差)来惩罚过大的权重参数。最常见的形式就是所谓的L2正则(L2 regularization,有时也被称为权重衰减,L2收缩):
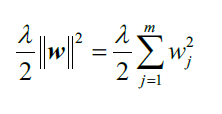
此处的就是正则化系数。
Note 正则化是为什么特征缩放如此重要的另一个原因。为了正则化起到作用,我们需要保证所有的特征都在可比较范围(comparable scales)。
如何应用正则化呢?我们只需要在现有损失函数基础上添加正则项即可,比如对于逻辑回归模型,带有L2正则项的的损失函数:
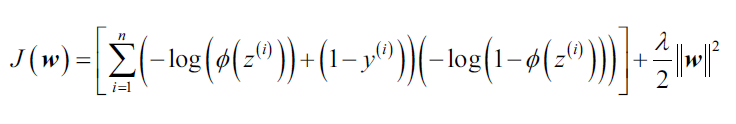
通过正则系数,我们可以控制在训练过程中使得参数
比较小。
值越大,正则化威力越强大。
现在我们可以解释LogisticRegression中的参数C:
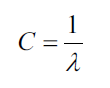
所以,我们可以将逻辑回归 正则化的损失函数重写为
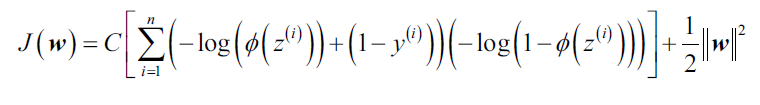
如果我们减小C的值,也就是增大正则系数的值,正则化项的威力也增强。
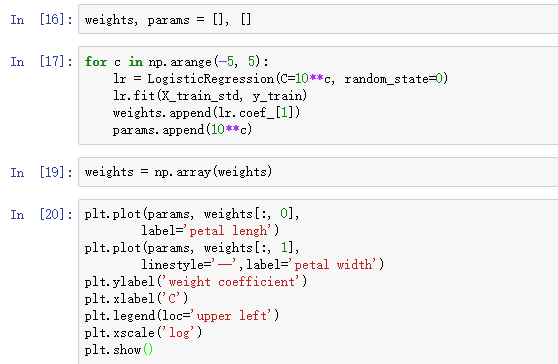
执行上面的代码,我们训练了十个带有不同C值的逻辑回归模型。
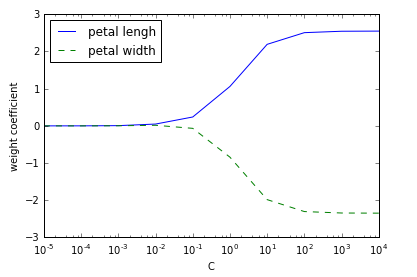
我们可以看到随着C的减小,权重系数也减小。
Note 本章只是简要介绍了逻辑斯蒂回归模型,如果你还意犹未尽,推荐阅读 Logistic Regression: From Introductory to Advanced Concepts and Applications, Sage Publications.