使用核PCA进行非线性映射
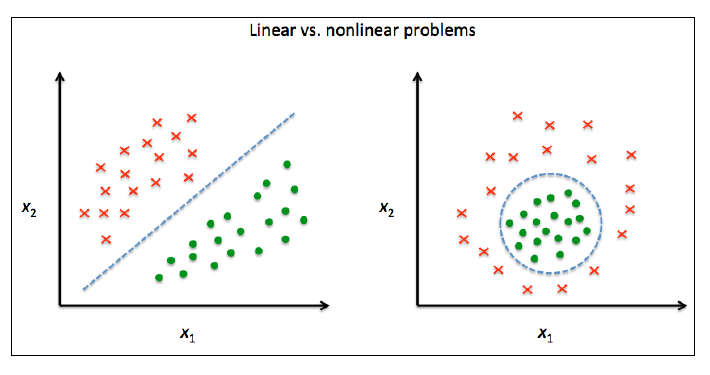
许多机器学习算法都有一个假设:输入数据要是线性可分的。感知机算法必须针对完全线性可分数据才能收敛。考虑到噪音,Adalien、逻辑斯蒂回归和SVM并不会要求数据完全线性可分。
但是现实生活中有大量的非线性数据,此时用于降维的线性转换手段比如PCA和LDA效果就不会太好。这一节我们学习PCA的核化版本,核PCA。这里的"核"与核SVM相近。 运用核PCA,我们能将非线性可分的数据转换到新的、低维度的特征子空间,然后运用线性分类器解决。
核函数和核技巧
还记得在核SVM那里,我们讲过解决非线性问题的手段是将他们映射到新的高维特征空间,此时数据在高维空间线性可分。为了将数据映射到高维k空间,我们定义了非线性映射函数
:
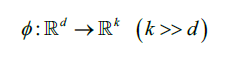
我们可以把核函数的功能理解为:通过创造出原始特征的一些非线性组合,然后将原来的d维度数据集映射到k维度特征空间,d<k。举个例子,特征向量,x是列向量包含d个特征,d=2,可以按照如下的规则将其映射到3维度特征空间:
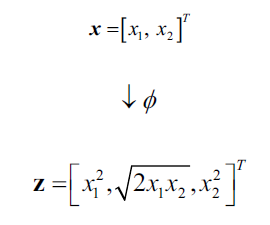
同理核PCA的工作机制:通过核PCA的非线性映射,将数据转换到一个高维度空间,然后在这个高维度空间运用标准PCA重新将数据映射到一个比原来还低的空间,最后就可以用线性分类器解决问题了。不过,这种方法涉及到两次映射转换,计算成本非常高,由此引出了核技巧(kernel trick)。
使用核技巧,我们能在原始特征空间直接计算两个高维特征向量的相似性(不需要先特征映射,再计算相似性)。
在介绍核技巧前,我们先回顾标准PCA的做法。我们按照如下公式计算两个特征k和j的协方差:
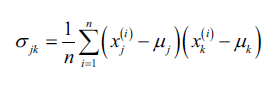
由于我们对数据已做过标准化处理,特征平均值为0,上式等价于:
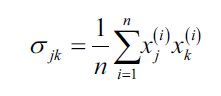
同样,我们能够得到协方差矩阵:
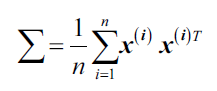
Bernhard Scholkopf(B. Scholkopf, A.Smola, and K.R. Muller. Kernel Principal Component Analysis. pages 583-588, 1997)得到了上式的泛化形式,用非线性特征组合替换原始数据集两个样本之间的点乘:
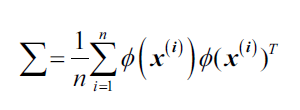
为了从协方差矩阵中得到特征向量(主成分),我们必须求解下面的等式:
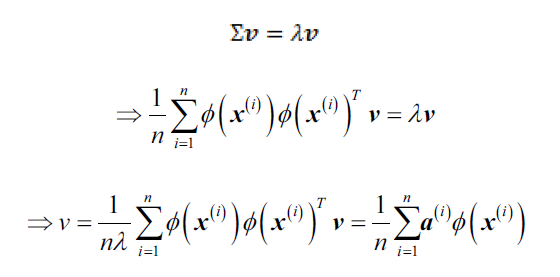
其中,是协方差矩阵
的特征值和特征向量,
的求法见下面几段内容。
我们求解核矩阵:
首先,我们写出协方差矩阵的矩阵形式,是一个n*k的矩阵:
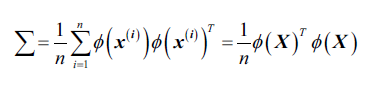
我们将特征向量写作:
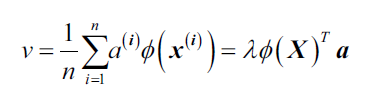
由于,得:
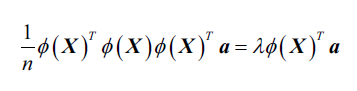
等式两边左乘:
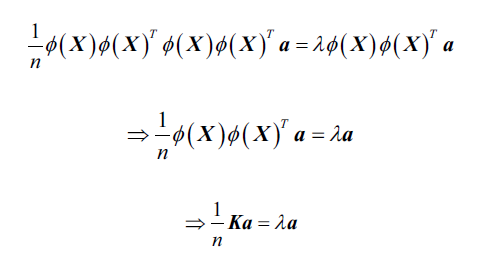
这里的就是相似性(核)矩阵:
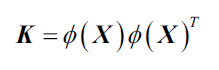
回忆核SVM我们使用核技巧避免了直接计算:
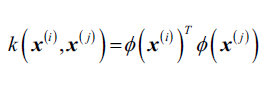
核PCA同样不需要像标准PCA那样构建转换矩阵,我们使用核函数代替计算。所以,你可以把核函数(简称,核)理解为计算两个向量点乘的函数,结果可看做两个向量的相似度。
常用的核函数有:
- 多项式核:
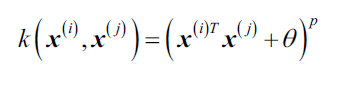 ,
,是阈值,
是由用户设定的指数。
- 双曲正切(sigmoid)核:
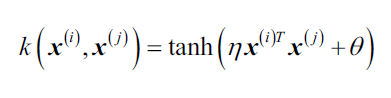
- 径向基函数核(高斯核):
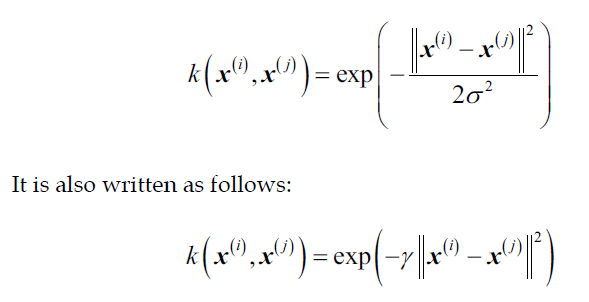
现在总结一下核PCA的步骤,以RBF核为例:
1 计算核(相似)矩阵k,也就是计算任意两个训练样本:
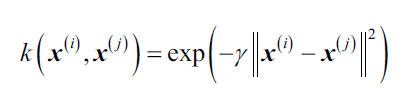
得到K:
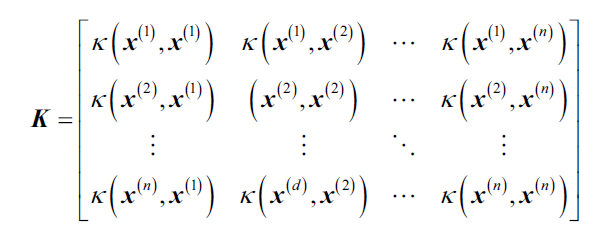
举个例子,如训练集有100个样本,则对称核矩阵K的维度是100*100。
2 对核矩阵K进行中心化处理:
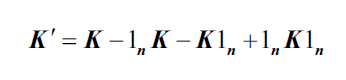
其中,是n*n的矩阵,n=训练集样本数,
中每个元素都等于
.
3 计算的特征值,取最大的k个特征值对应的特征向量。不同于标准PCA,这里的特征向量并不是主成分轴。
第2步为什么要计算? 因为在PCA我们总是处理标准化的数据,也就是特征的平均值为0。当我们用非线性特征组合
替代点乘时,我们并没有显示计算新的特征空间也就没有在新特征空间做标准化处理,我们不能保证新特征空间下的特征平均值为0,所以要对K做中心化。