处理缺失值
现实中的数据总是存在或多或少的缺失值现象。原因多种多样,可能是数据收集阶段发生错误,也可能数据调研阶段某些选项没有被填写。不论是什么原因造成的缺失值,我们都统一将其看做空格或者用NaN(Not a Number)表示的占位符。
不幸地是,大多数计算工具不能处理缺失值,即使我们忽略缺失值也不能产生预测结果。因此,我们必须认真对待缺失值问题。在讨论处理缺失值的方法之前,我们先创建一个例子,以便更好地理解缺失值问题:
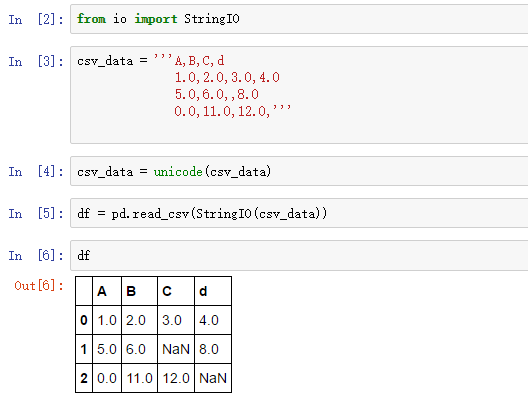
上面的代码,我们创建了一个csv格式的变量csv_data, 然后读入DataFrame对象,注意其中两个缺失值被NaN替代了。
如果DataFrame对象包含的数据很多,人工来查找NaN就不现实了。我们可以使用isnull方法来返回一个值为布尔类型的DataFrame,判断每个元素是否缺失,如果元素缺失,值为True。然后使用sum方法,我们就能得到DataFrame中每一列的缺失值个数,还是看代码理解吧:
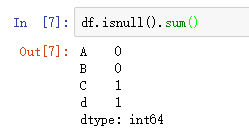
现在我们知道如果统计DataFrame每一列中的缺失值个数。下一节我们学习几种处理缺失值的策略。
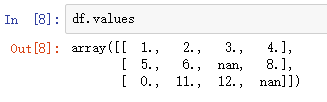
Note 虽然scikit-learn和NumPy数组结合的很方便,但是预处理时还是推荐使用pandas的DataFrame格式而非NumPy数组。由DataFrame对象得到NumPy数组很方便,直接通过values属性即可,然后就可以用sklearn中的算法了: