决策树学习
如果我们在意模型的可解释性,那么决策树(decision tree)分类器绝对是上佳的选择。如同名字的字面意思,我们可以把决策树理解为基于一系列问题对数据做出的分割选择。
举一个简单的例子,我们使用决策树来决定某一天的活动:
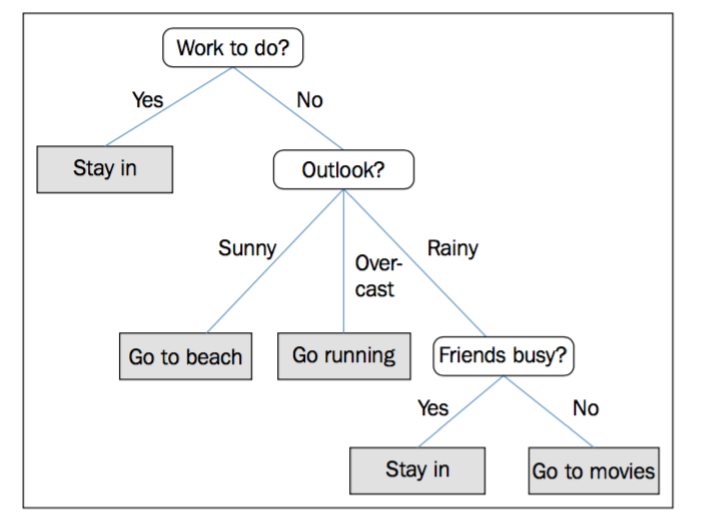
基于训练集中的特征,决策树模型提出了一系列问题来推测样本的类别。虽然上图中做出的每个决策都是根据离散变量,但也可以用于连续型变量,比如,对于Iris中sepal width这一取值为实数的特征,我们可以问“sepal width是否大于2.8cm?”
训练决策树模型时,我们从根节点出发,使用信息增益(information gain, IG)最大的特征对数据分割。然后迭代此过程。显然,决策树的生成是一个递归过程,在决策树基本算法中,有三种情形会导致递归返回:(1)当前节点包含的样本全属于同一类别,无需划分;(2)当前属性集为空,或是所有样本在所有属性上取值相同,无法划分;(3)当前节点包含的样本集合为空,不能划分。
每一个节点的样本都属于同一个类,同时这也可能导致树的深度很大,节点很多,很容易引起过拟合。因此,剪枝操作是必不可少的,来控制树深度。