将数据集分割为训练集和测试集
本节,我们使用一个新的数据集:Wine。Wine也属于UCI开源数据集,它包含178个样本,每个样本有13维度特征,描述了不同的化学属性。
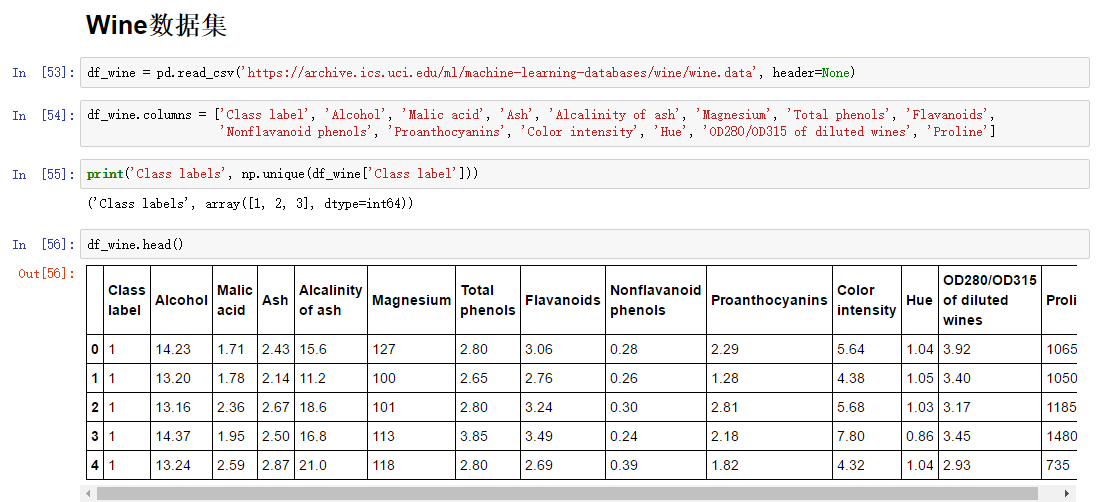
Wine数据集一共有三个类别:1,2和3.表示三个葡萄品种。
首先将数据集随机分割为训练集和测试集,一种简单的方法是使用sklearn.cross_validation中的train_test_split方法:

解释一下上面的代码: 首先,我们将特征矩阵赋值给X,将类别向量赋值给y,然后调用train_test_split方法随机分割X和y。通过设置test_size=0.3,使得训练集占Wine样本数的70%,测试集占30%。
Note 在分割数据集时,如果确定训练集和测试集的大小没有通用的做法,一般我们选择60:40, 70:30或者80:20。对于大数据集,90:10甚至 99:1也是比较常见的。还要注意的是,通过本地验证得到最优模型和参数时,还要在整个数据集(训练集+验证集+测试集)上训练一次,得到最终的模型。