基于Iris数据集训练感知机模型
我们使用Eirs数据集检验上面的感知机代码,由于我们实现的是一个二分类感知机算法,所以我们仅使用Iris中Setosa和Versicolor两种花的数据。为了简便,我们仅使用sepal length和petal length两维度的特征。记住,感知机模型不局限于二分类问题,可以用通过One-vs-All技巧扩展到多分类问题。
One-vs-All(OvA)有时也被称为One-vs-Rest(OvR),是一种常用的将二分类分类器扩展为多分类分类器的技巧。通过OvA技巧,我们为每一个类别训练一个分类器,此时,对应类别为正类,其余所有类别为负类。对新样本数据进行类别预测时,我们使用训练好的所有类别模型对其预测,将具有最高置信度的类别作为最后的结果。对于感知机来说,最高置信度指的是网络输入z绝对值最大的那个类别。
回到刚才的Iris数据集,我们使用pandas读取数据,然后通过pandas中的tail方法输出最后五行数据,看一下Iris数据集格式:
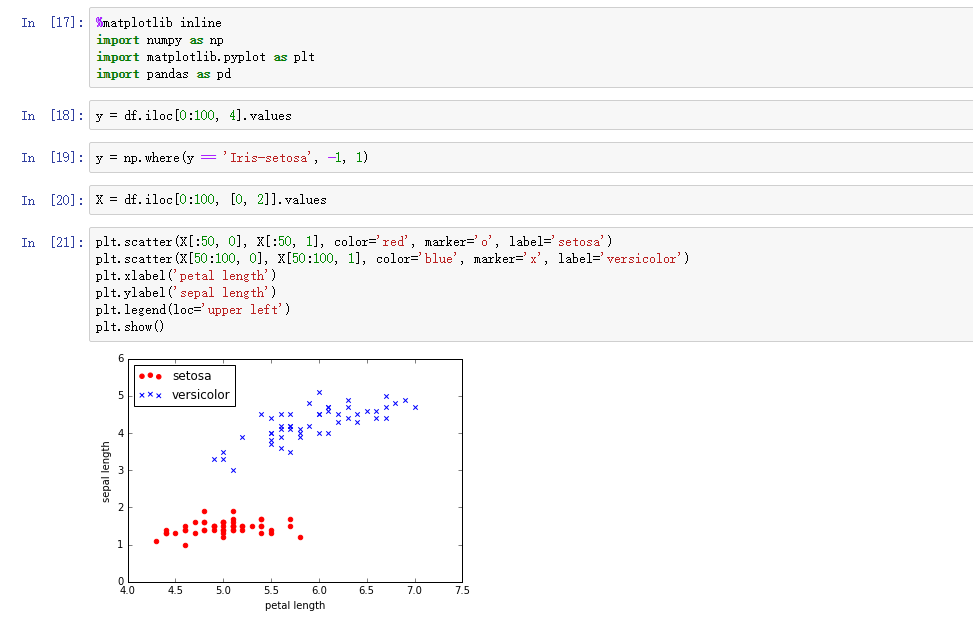
接下来我们抽取出前100条样本,这正好是Setosa和Versicolor对应的样本,我们将Versicolor对应的数据作为类别1,Setosa对应的作为-1。对于特征,我们抽取出sepal length和petal length两维度特征,然后用散点图对数据进行可视化:
现在开始训练我们的感知机模型,为了更好地了解感知机训练过程,我们将每一轮的误分类数目可视化出来,检查算法是否收敛和找到分界线:
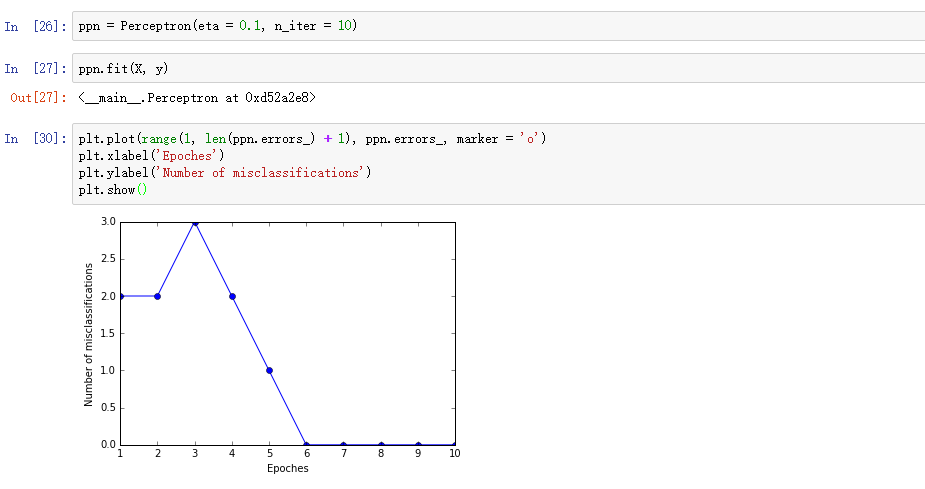
通过上图我们可以发现,第6次迭代时,感知机算法已经收敛了,対训练集的预测准群率是100%。接下来我们将分界线画出来:
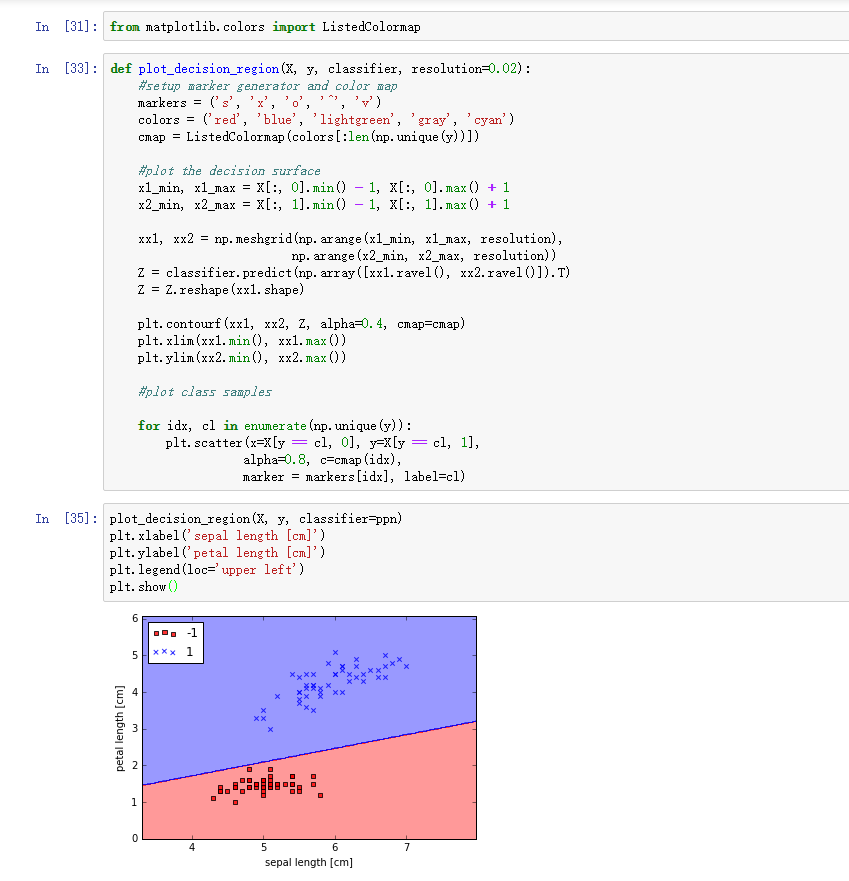
虽然对于Iris数据集,感知机算法表现的很完美,但是"收敛"一直是感知机算法中的一大问题。Frank Rosenblatt从数学上证明了只要两个类别能够被一个现行超平面分开,则感知机算法一定能够收敛。然而,如果数据并非线性可分,感知计算法则会一直运行下去,除非我们人为设置最大迭代次数n_iter。