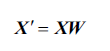有了转换矩阵,我们就可以将原始数据映射到新的特征空间了:
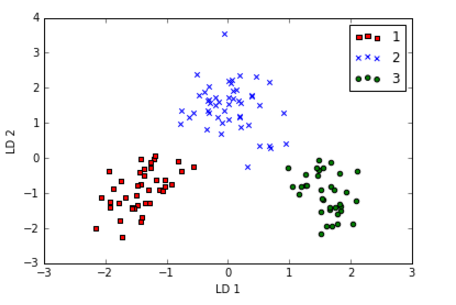
新数据集,明显线性可分:
我们通过一步步地实现LDA来加深理解,现在看看sklearn中如何使用现成的LDA:
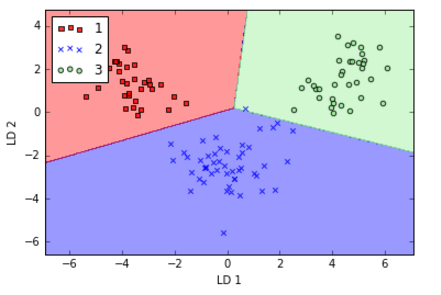
有一个样本被错分类:
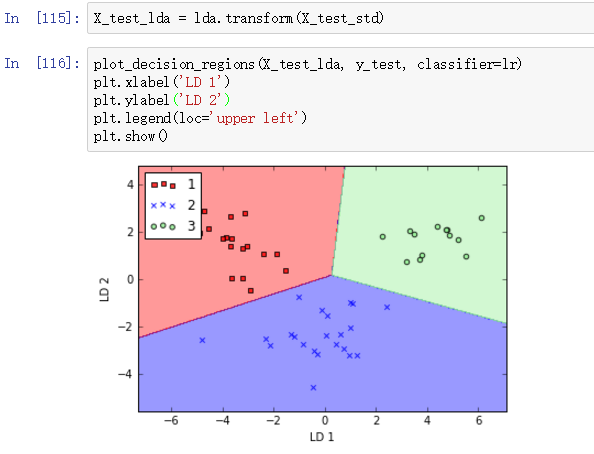
如果降低正则项的影响,完全正确分类训练集。当然了,过拟合并没有什么好处。我们看一下现在模型对测试集的分类效果:
Wow!100%的准确率。