通过管道创建工作流
当我们应用不同的预处理技巧时,比如对特征标准化、对数据主成分分析,我们都需要重复利用某些参数,比如对训练集标准化后还要对测试集进行标准化(二者必须使用相同的参数)。
本节,你会学到一个非常有用的工具:管道(pipeline),这里的管道不是Linux中的管道,而是sklearn中的Pipeline类,二者做的事情差不多。
读取Breast Cancer Wisconsin数据集
本章,我们要用到一个新的二分类数据集 Breast Cancer Wisconsin,它包含569个样本。每一条数据前两列是唯一的ID和相应的类别值(M=恶性肿瘤,B=良性肿瘤),第3-32列是实数值的特征。
话不多说,先读取数据集,然后将y转为0,1:
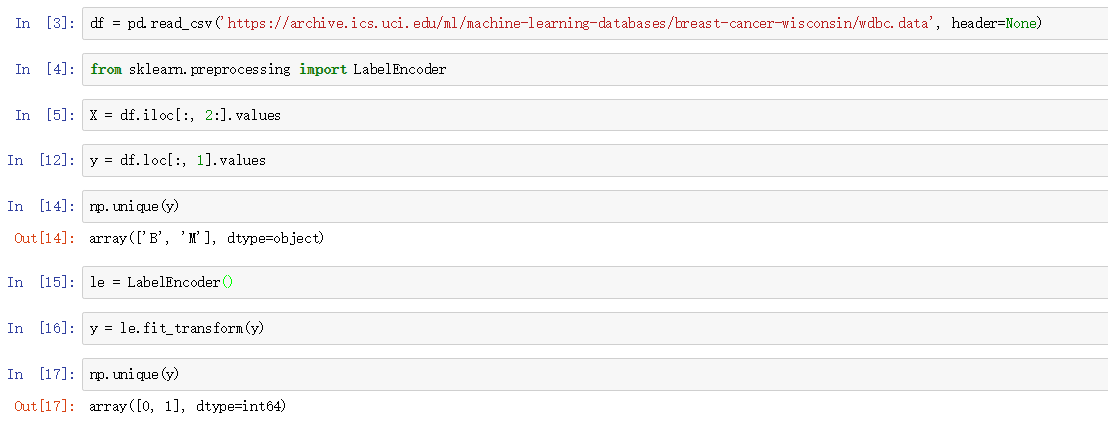
接着创建训练集和测试集:
将transformer和Estimator放入同一个管道
前几章说过,很多机器学习算法要求特征取值范围要相同。因此,我们要对BCW数据集每一列做标准化处理,然后才能应用到线性分类器。此外,我们还想将原始的30维度特征压缩的2维度,这个交给PCA来做。
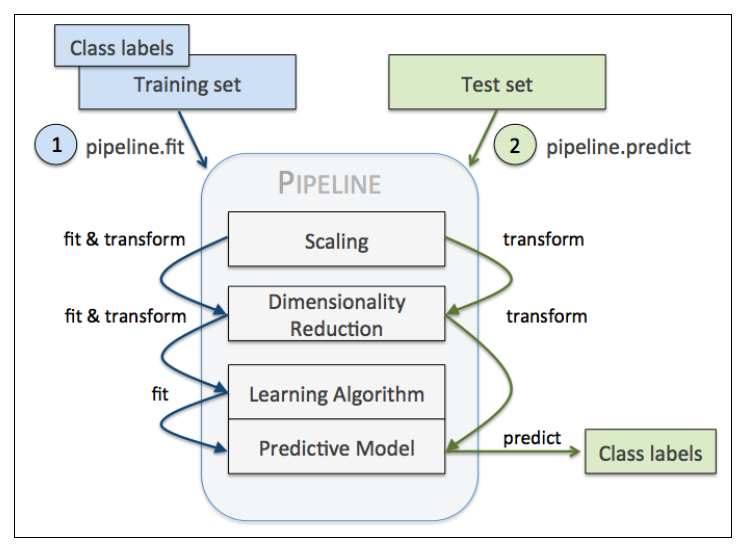
之前我们都是每一步执行一个操作,现在我们学习用管道将 StandardScaler, PCA和LogisticRegression连接起来:
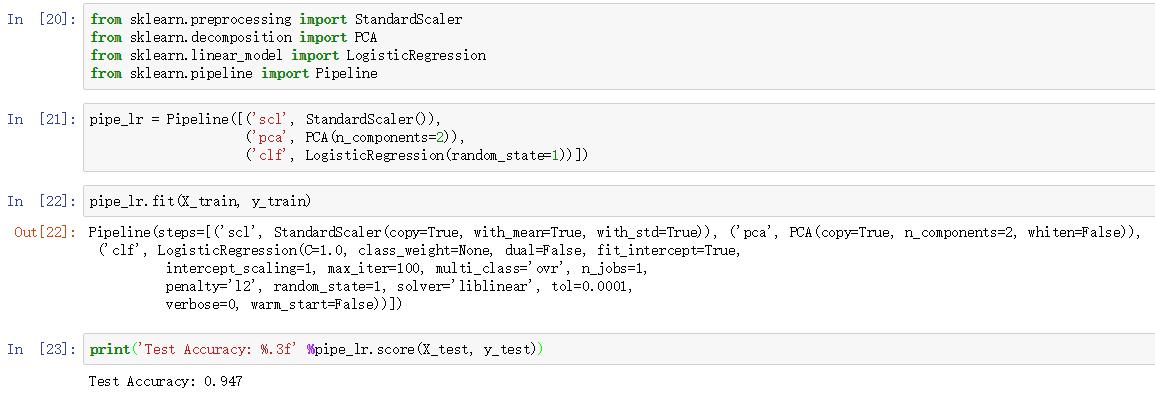
Pipeline对象接收元组构成的列表作为输入,每个元组第一个值作为变量名,元组第二个元素是sklearn中的transformer或Estimator。
管道中间每一步由sklearn中的transformer构成,最后一步是一个Estimator。我们的例子中,管道包含两个中间步骤,一个StandardScaler和一个PCA,这俩都是transformer,逻辑斯蒂回归分类器是Estimator。
当管道pipe_lr执行fit方法时,首先StandardScaler执行fit和transform方法,然后将转换后的数据输入给PCA,PCA同样执行fit和transform方法,最后将数据输入给LogisticRegression,训练一个LR模型。
对于管道来说,中间有多少个transformer都可以。管道的工作方式可以用下图来展示(一定要注意管道执行fit方法,而transformer要执行fit_transform):