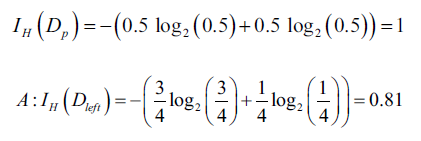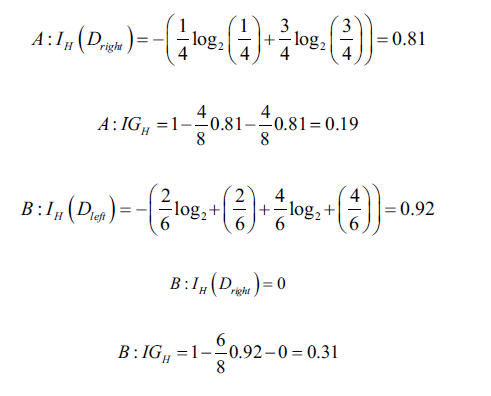最大信息增益
为了使用最大信息增益的特征分割数据,我们需要定义一个在决策树学习过程中的目标函数。此处,我们的目标函数是在每一次分割时最大化信息增益,我们定义如下:
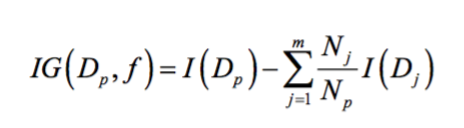
其中,f是具体的特征,是当前数据集和用特征f分割后第j个子节点的数据集,I是某种度量,
是当前数据集样本个数,
是第j个子节点的数据集中样本个数。为了简化和减小搜索空间,大多数决策树(包括sklearn)都是用二叉树实现的。这意味着每一个父节点被分割为两个子节点,
:
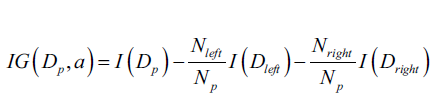
常用的度量I包括基尼指数(Gini index, )、熵(Entropy,
)和分类错误(classification error,
)。我们以熵为例:
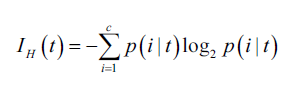
此处,指的是在节点t中属于类别c的样本占比。所以如果某个节点中所有样本都属于同一个类,则熵为0,如果样本的类别时均匀分布,则熵最大。比如,在二分类情况下,如果p(i=1|t)=1或p(i=0|t)=0,则熵为0.因此,我们说熵的评价标准目的是最大化树中的互信息。
基尼系数可以被理解为最小化误分类的概率:
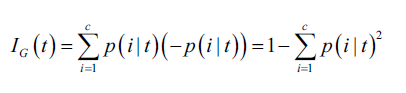
和熵一样,如果节点中样本的类别均匀,则基尼系数最大,比如,在二分类情况下:
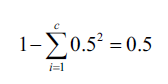
通常,熵和基尼系数的结果相似,所以不需要花太多时间在选择度量上面。
另一种常用的度量是分类误差:
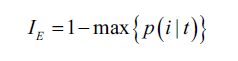
这个度量更建议在剪枝时使用,而不是在构建决策树时使用。举个简单的例子,说明一下为什么不建议构建树时用:
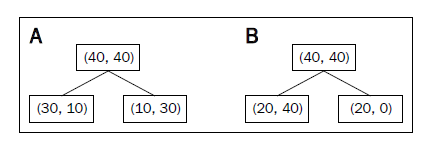
中包含40个正例样本和40个负例样本,然后分割为两个子节点。信息增益使用分类误差作为度量,得到的值在A、B情况下相同,都是0.25,计算过程如下:
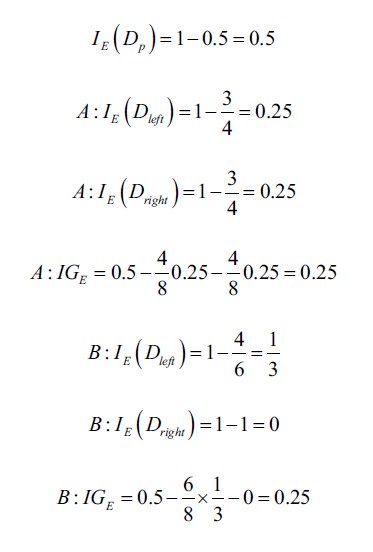
如果使用基尼系数,则会按照B情况分割:
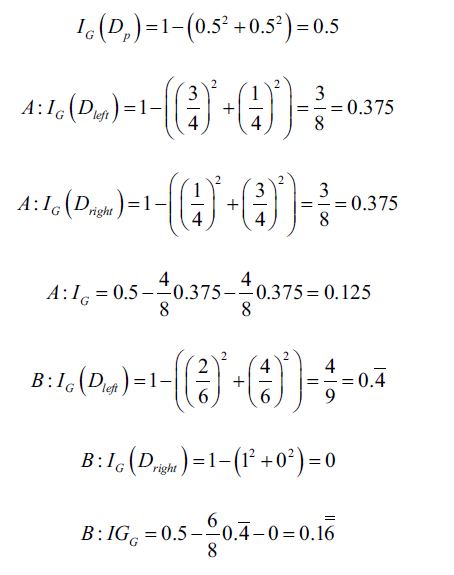
同样,如果用熵作为度量,也会按照B分割: